
You are browsing the Musical Myths category
A neutral 3rd lies exactly between a minor 3rd and a major 3rd. They say that major chords sound happy and minor chords sound sad, so neutral chords (also known as Swiss chords) must sound vague and neutral am I right? They must sound a bit comme ci comme ca, a bit grey?
To me this is utter nonsense. Whatever neutral chords sound like, they ain’t neutral, they’re actually punchy as hell. There is often a quality of tension, but sometimes not. Depending on what comes before it, you can easily mistake a neutral chord for a minor or major.
If major is happy,
And minor is sad,
Neutral is angry,
Suspicious,
Disappointed,
Gritty,
Peppery,
Quizzical,
Cute,
Crunchy,
Alerting,
And many such things (take your pick).
Just, whatever you do, don’t say that neutral sounds neutral.
What does it mean to be out of tune? First we need to look at what it means to tune. To tune is to bring an instrument to the desired pitch. The desired pitch. Desired is subjective because it is unique to your own perspective.
Calling something out of tune reflects your expectations as much as the music itself.
Why is music commonly perceived as out of tune? It’s because the heard pitches don’t align with expectation. Pitch expectation comes from musical exposure. Every culture has its own standard way of intonating pitches. If you’re musically trained then this expectation effect is even stronger.
This is normal and you’re entitled to your own biases in pitch expectation.
It’s often the hearing of other cultures’ music that causes the experience of out-of-tuneness. The feeling may also come when listening to xenharmonic music (music that uses tuning systems which sound radically different to the 12-tone equally tempered system).
There may also be innate psychoacoustic factors for experiencing something as out of tune, but I’m writing only about the learned factors today.
Experiencing something as out of tune is usually a good thing because, in most cases as musicians, we’re playing in groups, with others of a shared musical heritage, therefore we rely on traditional pitch expectations to provide the structure for cooperation. By noticing out-of-tuneness and adjusting intonation accordingly, the ensemble produces a more harmonious result.
As a musician of the xenharmonic tradition, I often receive comment that my music sounds out of tune. Yes, these new pitch relationships do sound out of tune at first. If you’re intrigued, you might relisten until new pitch expectations form within you. Then the music starts to sound in tune. It’s a wonder how flexible the mind can be.
Traditional intonation means tuning systems which are informed by culture and emerged over time due to technical, material and social reality. For example 12-equal, maqamat, ragas, slendro etc.
Notice how I put (for example) 12 and maqam in the same pot, despite one being considered microtonal and the other not. But indeed these systems are more comparable to each other than to non-traditional intonation.
Traditional intonation is powerful because there are large repertoires of traditional music to use it. Instrument designs are well known and produced in quantity. Music teachers have mastered traditional intonation and can readily teach it.
Some instrument makers simply tune newly-built instruments to recordings of similar instruments in the past. I have heard this is sometimes true of gamelan. That’s one way intonation can be passed down through a culture.
When you get into another culture’s traditional music, you can’t help but learn about their language, spirituality, food and other things. So people do find this a rewarding fun time.
When you listen to traditional music and realise that other people tune instruments differently, it may open a gateway to more broadly caring about intonation in music.
My own gateway into valuing intonation was by enjoying gamelan music. But actually the reason I’m still here is because I later discovered non-traditional intonation and I love it.
Non-traditional intonation is more about an individual musician’s needs for the music. Often the tuning is bespoke designed for a specific composition.
Intonation is just another musical parameter that us musicians use to more finely hone our expression. Intonation is the same kind of thing as tempo, dynamics, timbre. Learn one more thing and improve your craft.
You can’t walk into a guitar shop and buy a 17ed2 guitar off the shelf. That’s why musicians who work with non-traditional intonation are necessarily tinkerers and builders who face unique challenges. Or they pay big sums for bespoke instruments.
Performers who are faced with the task of playing music written in non-traditional tuning systems often must learn new techniques to get at those new pitches. No doubt this is a barrier to getting music performed in unconventional tunings.
Non-traditional intonation (e.g. triple Bohlen-Pierce, 22ed2, Carlos Alpha, 88cet, blackwood[10] etc.) is less explored, so there exists less repertoire, fewer instruments, fewer music teachers to guide you. Are these downsides, or opportunities?
(Random aside, but imagine if a currently non-traditional tuning system became traditional somewhere in the future, wouldn’t that be cool? An island of people jamming in dekany scales? A valley of the Bohlen-Pierce flutes?)
Building instruments is hard, but digital music tech is better at adopting new tuning functionality. This makes it easier to try out both traditional intonations of other cultures, and non-traditional tunings that will get everyone thinking in new ways.
The online tuning discussion space is broadly split between traditionalists (including historians) and non-traditionalists, with some overlap but not particularly much. We’re all here because we appreciate intonation, but we’re not always on the same page about the point of it all.
Is microtonality just about using small melodic runs? Is it about using non-12 tunings? Is it about using non-Western tunings? Is it about preservation of tuning customs? Is it a new frontier of previously unheard melodies? Ask and you shall get different answers.
My approach in the past was to see microtonality as music that uses tunings that are non-12. But after many years, the 12 vs non-12 dichotomy seems less pertinent than I was originally made to believe.
When you start thinking of microtonality as “any tuning system that isn’t 12-equal” then you have a combination of well-beloved traditional intonations with experimental non-traditional stuff. But these are unlikely partners.
When I release an album of 100% non-traditional intonation stuff, isn’t it just as fair to call it non-maqam as it is to call it non-12?
And yet, I promoted a lot of my old music as “not 12” because that was the thing to do in microtonal circles. Now I am starting to realise the traditional vs non-traditional dichotomy is more pertinent.
Paraphrasing something said to me recently IRL: “people from other cultures must understand your music more easily because their music is microtonal too.” On this face of it, this must have sounded reasonable, yet I don’t have any evidence for the claim. Could it be that the 12-vs-non-12 framing make this assumption sound more reasonable than it is?
The first time I heard Bohlen-Pierce music it sounded weird to me. When I played it to my friend who mastered santoor in North Indian classical music, it sounded weird to him too. It makes no difference that BP and ICM are both considered microtonal. BP sounds weird to all.
Paraphrasing from a recent Facebook microtonal group post: “I am used to ancient Greek modes so why don’t I get Balinese music?” Just because both are labelled microtonal, doesn’t mean there is no relearning for your ear to do.
Thought experiment: A Turkish person walks into a shop, buys a saz and records a hit tune with a melody in makam bayati, using all the techniques they learned from their music teacher. People enjoy the music, everyone is having a good time.
A French person walks into a shop, buys a guitar and records a hit tune with a melody in the minor scale, using all the techniques they learned from their music teacher. People enjoy the music, everyone is having a good time.
In both the hypothetical examples above, the musicians walked a well trodden path, and fair play to them; they shared the love of music. The Turkish example is awarded the (perhaps desirable) label “microtonal”, whereas the French example is not. And yet I consider both of them to have followed traditional intonation and both of value.
And then I’m over here recording tunes in glacial[7], CPS scales, machine[6], 88cet, 4L3s, which are all microtonal, so people consider my music to be closer to the Turkish example than the French, when I’m actually unconventional towards both. Don’t you find that perspective to be nonsensical?
Another thing is – I do love 12-equal! I mostly listen to video game soundtracks and dig up 80s and 90s dance music. I’ve had all kinds of feelings and experiences to music in 12. I will always enjoy music in a range of different intonations, including 12.
What I want to convey is that there is a positive case for intonation as a way to further hone your musical expression. I also want to convey that when we define microtonality negatively as being in opposition to one particular tuning system then we cause confusion about how those other varied tuning systems fit in together. I did my best to share this perspective on microtonality, and while I’m not a very good writer I still hope it made you think a couple thoughts.
Here are some of my thoughts on various microtonal scales. These thoughts are my own subjective impressions and there’s no need to take them seriously. Enjoy!
What are your own impressions?
In discussion of musical tuning there is often talk about “equal divisions” of an octave or other interval. There is potential here for confusion as there are two different ways of equally dividing an octave.
Wait, two ways? You’d think there was only one way to divide an octave equally. You make all the notes the same size! But I’m being serious. You can equally divide an interval either arithmetically or logarithmically.
Arithmetically equal = each step is the same Hz difference from the next
Logarithmically equal = each step is the same ratio difference from the next
Let’s say you have two notes, A 440Hz and A’ 880Hz. The interval between these two notes is an octave. If I want to divide this octave into arithmetically equal notes then we simply split it in a way that the difference in frequencies are equal.
For example we could split it into 8 intervals. We get the difference between the two notes by subtracting the frequencies. 880 – 440 = 440. Then divide this into 8. 440 / 8 = 55. So the base step size is 55Hz.
Constructing the scale is done by starting from 440Hz and then adding 55Hz each time until we reach the octave at 880Hz:
| 440Hz | 495Hz | 550Hz | 605Hz | 660Hz | 715Hz | 770Hz | 825Hz | 880Hz | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 55Hz | 55Hz | 55Hz | 55Hz | 55Hz | 55Hz | 55Hz | 55Hz | ||||||||||
| 9/8 | 10/9 | 11/10 | 12/11 | 13/12 | 14/13 | 15/14 | 16/15 | ||||||||||
Each note is 55 Hz apart from the next. You can move up and down the scale by adding/subtracting 55 Hz. The result is the harmonic series segment 8:9:10:11:12:13:14:15:16 with a fundamental frequency of 55 Hz. This scale sounds nothing at all like the equal tempered scale, in fact it sounds similar to the scales you get by playing harmonics on a guitar string.
To hear what it sounds like, you can follow this Scale Workshop link – it will open a page where you can press qwerty keys to play in this tuning.
Let’s take the octave from A 440Hz to A’ 880Hz and look at it as a ratio. 880/440. This can be simplified to 2/1.
To divide 2/1 into 12 logarithmically equal steps we need to find the step size. 2/11/12 = 1.05946309436 (approx).
Constructing the scale is done by starting from 440 Hz and then multiplying this value by the step size 1.05946309436 twelve times until we reach 880 Hz:
| 440Hz | 466.16Hz | 493.88Hz | 523.25Hz | 554.37Hz | 587.33Hz | 622.25Hz | 659.25Hz | 698.46Hz | 739.99Hz | 783.99Hz | 830.61Hz | 880Hz | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 26.16Hz | 27.72Hz | 29.37Hz | 31.12Hz | 32.96Hz | 34.92Hz | 37Hz | 39.21Hz | 41.53Hz | 44Hz | 46.62Hz | 49.39Hz | ||||||||||||||
| 1.059 | 1.059 | 1.059 | 1.059 | 1.059 | 1.059 | 1.059 | 1.059 | 1.059 | 1.059 | 1.059 | 1.059 | ||||||||||||||
These steps don’t look equal in terms of frequency – the Hz values get larger with every step. Maybe by now you have noticed one way in which the steps are equal… Each step is an equal ratio difference from the next.
To hear what it sounds like (I mean it’s just 12edo at A440Hz), you can follow this Scale Workshop link – it will open a page where you can press qwerty keys to play in this tuning.
In an equal temperament, you can modulate between keys and every key will sound equally in-tune. Whereas arithmetic divisions will only give you perfectly-tuned harmonics of a single fundamental with no concept of tonal modulation.
Which of these two methods sound equal to the ear?
It’s the logarithmic version – also known as equal temperament or EDO (equal division of the octave).
When tuning theory people mention “equal” scales, safely assume that they’re probably talking about this method.
Equal temperaments sound equal because our perception of pitch is logarithmic itself. The hearing system isn’t listening out for equal difference in Hz, it’s listening out for equal difference in step size ratio. This isn’t immediately obvious until you’ve compared the two for yourself.
So this was just a quick and simple post to explain something that has caused a little confusion in the past. Hope someone will find it useful.
The golden ratio, also known as φ (phi) or approximately 1.618, is a number with some trippy properties. It’s no wonder that many people treat the golden ratio with a great deal of mysticism, because (here’s the cliche part) it appears repeatedly in nature and also crops up in many fields of mathematics. And we all know that mathematics is the language of the universe. Duuude.
So I want to talk a little about the golden ratio and how it might sound if we used it as a musical interval.
You may have seen or heard some youtube videos which exclaim “this is what the golden ratio sounds like!!” — These are almost always based on the decimal expansion of phi, where each digit is assigned to a note of the major scale. I won’t give an example here because it’s such an unimaginative Western-centric interpretation of nature’s finest ratio. Just imagine the background music for a shitty Google commercial, children and mothers playing, young trendy people smiling while looking into their laptops, and you get the idea.
Let’s have none of this. The truth is that the golden ratio, as a musical interval, is gritty, dirty, dissonant, inharmonic, and not remotely like you’d expect. And it’s explicitly microtonal.
Take for example John Chowning’s Stria, an important electronic work from 1977, using his then-new discovery of FM synthesis. The golden ratio is used as the interval between carrier and modulator, such that the resulting timbre is an inharmonic cloud of golden-ratio-related partials. To get a sense of what the golden ratio may sound like as a musical interval, start from here and let the sounds slowly work their way into your brain.

Here is something that causes confusion time and time again. There are two musical intervals which both claim to be the golden ratio! How is this possible?
Consider the octave in terms of cents. Cents are a musical measurement of pitch which divide the octave into 1200 logarithmically equal parts. This means that 200 cents is equivalent to an equal-tempered whole tone, 100 cents is equivalent to a semitone, 50 cents is equivalent to a quartertone, etc. So our first version of phi will simply divide 1200 by phi:
1200 / φ = 741.6407865 cents
~741 cents sounds like a horribly sharp fifth. Well, we already know that the golden ratio sounds dissonant, so this could be the golden ratio that we’re looking for. But first let’s look at the other contender:
1200 * log2(φ) = 833.090296357
While both of these intervals could be used to generate scales that you could play interesting music with, only one of them gives me that one-with-the-universe vibe. To find out why, we need to look at a psychoacoustic effect known as combination tones.

It is a simple fact of psychoacoustics that any two tones that you play will produce additional combination tones. There are two types of combination tone: difference tone and sum tone. The sum tone is calculated by summing the frequencies of the two tones. The difference tone is calculated by subtracting the frequency of one tone from the other.
Let’s play A (440Hz) and E (660Hz) on the keyboard and work out these combination tones for ourselves.
Difference tone = 660Hz - 440Hz = 220Hz Sum tone = 660Hz + 440Hz = 1100Hz
The difference tone sits an octave below the root note of A. This is the reason why you hear the missing fundamental being “filled in” by your brain when you play a power chord or a just major triad.
As for the sum tone, it is tuned to the 5th harmonic above that missing fundamental of 220Hz, because 220Hz*5=1100Hz. The 5th harmonic is a just major third plus two octaves. The sum tone is perhaps one of the reasons why the just major triad is such a stable and pleasing sonority.
Just to recap: If I play TWO tones (440Hz and 660Hz), your brain hears FOUR tones, (220Hz, 440Hz, 660Hz, 1100Hz). The effect is subtle, and the combination tones are heard a lot more softly than the real tones, but the effect can be perceived. Bearing that in mind, let’s work out the combination tones that appear when using the golden ratio interval.
We shall play a 1kHz tone and a ~1.618kHz tone. The interval between these two tones is the golden ratio of ~833 cents.
Difference tone = ~1.618kHz - 1kHz = ~0.618kHz Sum tone = 1kHz + ~1.618kHz = ~2.618kHz
What’s interesting about these combination tones is that they are themselves related to the original tones by the golden ratio. This is easy to demonstrate:
1kHz / ~0.618kHz = φ ~2.618kHz / ~1.618kHz = φ
All four of these tones are related by the golden ratio! If we calculate the 2nd order combination tones, 3rd order, and so on, we’ll find the same thing again and again. Every combination tone is connected to some other tone by the golden ratio. This is exactly the recursion effect that we expect to find when we use the golden ratio properly.
However this landscape of recursive inharmonic partials can best be described as a chaotic and complex mess. This is an extreme contrast to the use of the golden ratio in visual proportions, paintings, architecture, flowers and nautilus shells, which most people would agree appear harmonious and pleasing. But that’s just the truth of it. The ear works in weird ways. Not all visual forms have an analogue as sound.
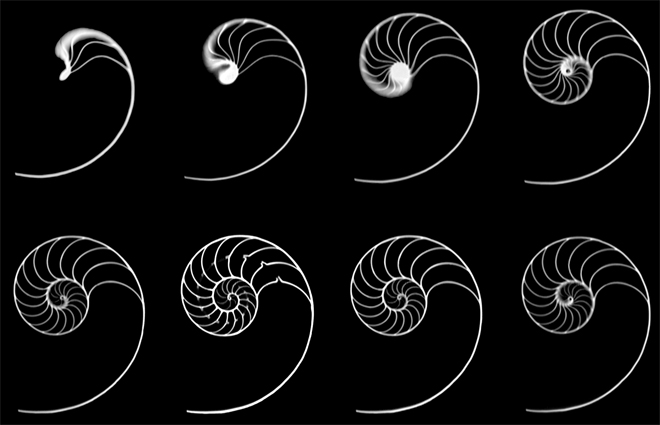
By now it should be clear that golden ratio music has some interesting properties that the Western equal-tempered scale could scarcely hope to reproduce. If you have some highly accurate micro-tunable instruments and perhaps some scale-designing software such as Scala, alt-tuner or LMSO, then your next step is to design a scale that features the golden ratio.
There are many possibilities when making your own phi-based scale, but today I will only give you one. Developing your own golden ratio scales is left to you as a rainy day exercise.
Almost all scales contain an interval of equivalence, and for most scales that interval is the octave. In octave-based systems, a note such as C appears many times, and each C is separated by one or more octaves.
By the way, an octave is a ratio of 2. If you play an A at 440Hz and then play the A’ one octave higher, the higher pitched note would be 880Hz.
For our scale, we want to pack in as many golden ratios as possible. There’s no room for any boring numbers such as 2. Indeed, our interval of equivalence will be the golden ratio itself. This means the scale will repeat after approximately 833 cents. This scale would fit snugly into the frequency space between 1kHz and ~1.618kHz.
Our next step is to divide this interval into smaller intervals (a & b). Each time we divide an interval into two intervals, those intervals should have the golden proportions.
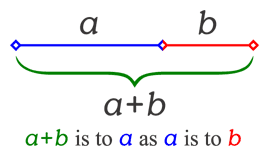
Then take the biggest interval that remains in the scale and break that down into 2 intervals with the golden proportion. Repeat this process until you have enough pitch material to write music with.
I’ve done all the calculations, and the resulting scale (taken to 8 steps) is presented below in Scala format so that you may try it out for yourself:
! sevish_golden.scl ! Scale based on the golden ratio 8 ! 121.546236174916 196.665941335636 318.212177510552 439.758413685468 514.878118846189 636.424355021105 711.544060181825 833.090296356741
Some interesting notes about the above scale… When generating the values, I noticed that the scale was a Moment of Symmetry (MOS) after 3, 5, 8 steps. Those are Fibonacci numbers. I stopped after 8 steps because it will map very nicely to a piano keyboard with linear mapping. With this mapping, you will always hear the golden ratio when you play a minor sixth on the keyboard. Coincidentally, this tuning has some fair approximations to the fifth, fourth, supermajor third, minor third, and major second.
If you want to find more tunings with the golden ratio, you might look at Heinz Bohlen’s 833 cent scale for inspiration.
When using scales that are based on the golden ratio, you will find that timbre makes a huge difference to the result. If you use an instrument that produces bright and clear harmonic overtones such as the violin or a sawtooth wave, you will hear an unruly clash of a harmonic timbre against an inharmonic scale.
Instead, you could take a similar approach to John Chowning and bake the golden ratio right into the timbre itself by using inharmonic overtones based on the golden ratio. Then suddenly your timbres and your scale will align, resulting in a much smoother sound. It’s just one more demonstration of the fact that tuning and timbre are deeply intertwined.
If you’re a computer musician, download a free copy of the Xen-Arts synth plugins. These instruments can produce inharmonic partials which can be controlled by the user. By default, they include a setting where each partial is tuned to some multiple of the golden ratio. These instruments could be a quick way to explore the topics I’ve been discussing in this post.
Vibrating strings produce (more or less) harmonic overtones. If two strings are tuned in some simple frequency ratio such as 3/2, 4/3 or 5/3, then those harmonic overtones match up nicely and avoid roughness. But if the two strings are tuned in some haphazard fashion then the overtones of each string won’t match up, causing the overtones to clash with each other.
We can actually plot out a graph which shows the interval between two strings and the corresponding dissonance. This is called a dissonance curve, and for a normal string it looks something like this:
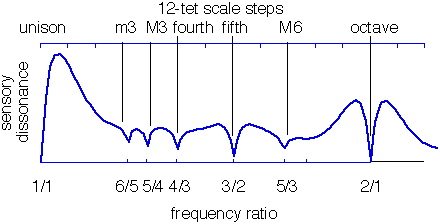
So what.
Well, imagine a weird kind of string that produces inharmonic overtones, such that the dissonance curve looks different to the one above. Because the dissonance curve is different, you couldn’t play Air on the G String and expect it to sound good. You could however write new music that would fit with the novel dissonance curve.
Today, such a string is more than just a mathematical curiosity. It exists in the physical world.
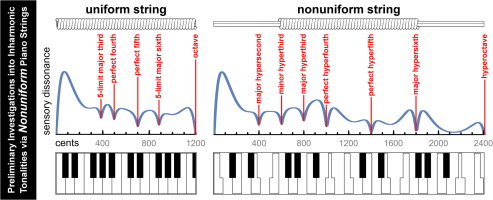
“Inharmonic Strings and the Hyperpiano” (by Kevin Hobby and William Sethares) is a paper published in Applied Acoustics. The strings in their hyperpiano have a stretched out dissonance curve where the double-octave sounds most consonant and the octave becomes dissonant. Okay so maybe it’s not going to be used on every new pop record, but this kind of freaky instrument can produce game-changing new tonalities.
Since the dissonance curve is stretched out to the double-octave or “hyperoctave”, Kevin Hobby suggests we might try tuning a hyperpiano instrument to 12 equal divisions of the hyperoctave. Wait, isn’t that just 6-EDO – a whole tone scale? Actually, it isn’t! They may be identical tunings, but the octave is considered a dissonant interval on the hyperpiano, analogous to the tritone on a normal piano. So it makes a lot more sense to describe this tuning as 12 equal divisions of the hyperoctave. Really.
The ringing of the strange hyperpiano sounds like a death bell for the unwavering cult-like belief in pure ratios and true frequencies. Tuning and timbre are deeply linked. If we’re willing to experiment with new timbres then we can uncover new musical vocabulary for the future to come.
The next step is to explore all this for yourself – download the sampled hyperpiano and give it a play.
What is the meaning of ET and EDO, and are they interchangeable?
ET: Equal Temperament
EDO: Equal Divisions of the Octave
In practice, yes they are interchangeable. For example, 12-ET and 12-EDO both refer to the exact same tuning which has 12 equal notes per octave. But there is a slight difference in their meaning.
12-ET suggests that the tuning is a temperament, i.e. it tempers some other interval, usually a just interval. 12-ET tempers 81/80, the syntonic comma, and other intervals.
12-EDO suggests that an octave has been divided into 12 equal parts, but otherwise doesn’t imply that tempering is of importance.
Some people will even say ET for 12-ET, 19-ET and 31-ET, while using EDO for 8-EDO, 13-EDO and others. Perhaps because 8-EDO and 13-EDO are not thought of as temperaments, whereas 12-ET, 19-ET and 31-ET are all useful meantone temperaments.
Personally, I always use EDO in my own thinking and private communication with other microtonalists, but will use TET or ET when I need to be understood by a larger, mixed audience.
To complicate things further, some people use ED2 or ED2/1 synonymously with EDO, because the octave is equal to the ratio 2/1. The good thing about this format is that we can generalise it for other scales that divide some interval into equal parts (e.g. EDphi, ED3/2, ED4). I welcome the move to this kind of generalised terminology that helps us describe more tunings with less words.
The world of xenharmonic jargon is often difficult to navigate. Once you get your head around it, you can forget about the tuning theory politics and remember that the important part is to make inspiring and enjoyable music!

And don’t get me started on those solfeggio frequency guys…
